
Slide Attacks
So we're taking a break from these cool and classic probabilistic cryptanalysis techniques and checking out slide attacks. Well, maybe it is a probabilistic attack too but I lack the vocabulary to find a better word to differentiate them. One thing is clear: we are not relying on deviations from perfect randomness to crack the code.
Check it out. After differential cryptanalysis got big, everyone and their dog was cracking variants of DES with it and applying it to all sorts of algorithms. One design strategy to counter DC (and linear attacks) was to add more rounds. This is generally a good way to improve the security of a cipher (at the cost of adding clock cycles). Then Alex Biryukov and David Wagner decided to stomp a mudhole in that theory. With their development of slide attacks, they showed that doing a million rounds of an insecure round function is not a secure design strategy. We'll wait a little bit before describing the details of the attack and what is required to implement it. A good rule of thumb for now is: If your round function sucks and you just repeat it using identical subkeys, your cipher is probably vulnerable to a slide attack.
Source Code
Here is some coded goodness. It performs the slide attack using 30 plaintext/ciphertext pairs. It repeats this process 1000 times for performance comparison versus brute force (also included in the code).Toy100 Slide Attack Code - [slide.c]
The Target

The cipher that we'll be going after is another simple toy that I came up with: Toy100. It is very weak but its simple structure and key/block size make it easy to crack by brute force and by slide attack in a reasonable amount of time on any PC. It takes an 8-bit input block, encrypts it with a 16-bit key, and outputs an 8-bit output block. The key itself is actually composed of two 8-bit subkeys (K0 and K1). The cipher consists of 100 rounds of a very simple round function (F). Each round XORs its input with a subkey and splits the result into two 4-bit blocks. These half-blocks are each run through a 4-bit substitution box and recombined resulting in the output of the round function.
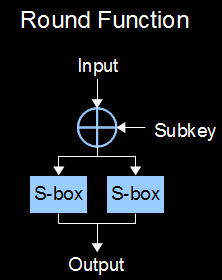
The key schedule is equally simple and is ultimately the reason that this cipher is vulnerable to a slide attack. Each round alternately uses subkey 0 and subkey 1. So round #1 would mix using K0, round #2 with K1, round #3 with K0, etc... This schedule repeats through all 100 rounds. You can check out the workings of the S-Box in the code, but it is irrelevant for this attack.
A known-plaintext attack on a single round of this would be trivial. Just take the known ciphertext and reverse it through the S-Boxes. Then XOR it with the cooresponding known plaintext. This recovers the subkey used in that round. The problem is that in the 100 round version, we don't access to the data going into and coming out of a single round. We can only get the original plaintext and the resulting ciphertext. If we wanted to recover the key in one shot, we would need to put a spy in the middle of the 100 rounds somewhere and thats not going to happen.
Requirements
To crack an algorithm more efficiently than by brute force via a slide, that algorithm must meet several requirements. It must be possible to break the structure down into many identical components. These groups of operations must be identical in how they process a block. They must also use the same keying material. It does appear that if the same subkeys are not used for every component but these subkeys are related (by some simple operation in the key schedule); the attack is still viable. The repeating components that make up the cipher must, alone, be "easy" to defeat via known-plaintext. The ease with which these subcomponents can be reversed to reveal their subkey when some plaintext+ciphertext is known will directly relate to how well the full slide attack works. You must have access to some plaintext-ciphertext pairs encrypted with a single key (as is standard in known-plaintext attacks).

Breaking the Double-round
The first step to defeating Toy100 is to find a repeating series of operations that use the same subkeys (described above as a "component"). Taking a look at the structure of the cipher should reveal an easy target: 2 rounds in a row. By dividing the cipher into a series of double-rounds, we get a pattern of repeating usage of K0 and K1. Since the mechanics of the combined two rounds never changes as it repeats 50 times while running through the cipher, this is a perfect candidate for building our attack. This two-round using K0 and K1 will henceforth be referred to as a "doubleround" or "double-round".
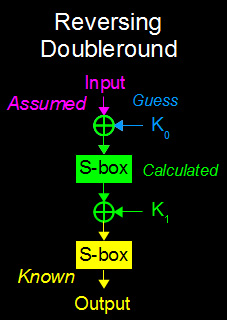
Recall that one of the requirements of the slide attack is that the doubleround be "easy" to attack on its own. So lets take a stab at that. When we check out how two rounds back-to-back looks, we immediately notice that the final substitution box can be ignored. This is because if we know the ciphertext, we can just run it backwards through the S-Box. Unlike attacking a single-round, we can't just do some XOR magic to recover the subkeys in one shot. That's ok, instead we'll make a bunch of guesses at K0. In fact, we'll guess every single possible K0 (256 in all). For each one, XOR it with the known-plaintext, run that through the first S-Box, then XOR that with the reverse-SBox'd known-ciphertext. This will recover the cooresponding K1 subkey for that K0 guess.
This process does NOT result in a single "answer". Instead, it gives us 256 possibilities for K0 and K1. We'll be using these candidate keys later to determine which one is correct.
Finding a Slid Pair
Alright, grab ahold of your thinking caps; this is the good stuff. The goal of a slide attack is to take a bunch of known-plaintext data and find two pairs of plaintext/ciphertext that relate to each other in a very specific way. To be clear: we need a P0 and C0 that have a relationship to another pair P1 and C1. If we can find this slid pair, the game is over and we win.
The relationship between the two pairs is as follows. When P0 is fed into the cipher, the ouput of the first doubleround is equal to P1. This makes the P1/C1 pair follow the exact same path through the cipher except offset by one doubleround. This also results in the final P1/C1 doubleround's input being equal to C0.
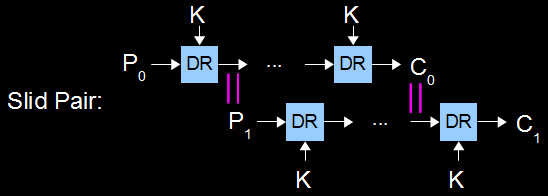
We can't look at P1/C1's final doubleround input. Its hidden from us by the cipher; all we get are C0 and C1 on the ciphertext end. So what you can do, given 2 plaintext/ciphertext pairs, assume that they are a slid pair. By doing so, we are pretending that C0 is equal to the input to C1's last doubleround function. We recover those 256 candidate K0/K1 using this assumption via the method described in previous section (reversing the double-round). Specifically, we treat C0 as the known-plaintext and C1 as the corresponding known-ciphertext. This will result in 256 possible K0/K1 subkeys.
Next, we use those 256 subkeys to check if the pair that generated them is a slid pair. Only one of those 256 is correct and even that prospect also relies on a slid pair having occurred at all. The check each one, we look over at the plaintext side of the cipher. Carry those guessed K0/K1s one pair at a time up to the beginning of the cipher. Encrypt the P0 from the assumed slid pair using those candidate subkeys, BUT ONLY DO IT FOR ONE DOUBLE-ROUND. Take this doubleround output and compare it with P1. If they match, it is a good bet that you have found a slid pair and that K0/K1 is the correct key. If you get this indication of a slid-pair, encrypt some of the known-plaintext through the full cipher using that guessed key to verify that it results in the proper ciphertext. If so, congratulations: you have recovered the key.
Implementation and Performance
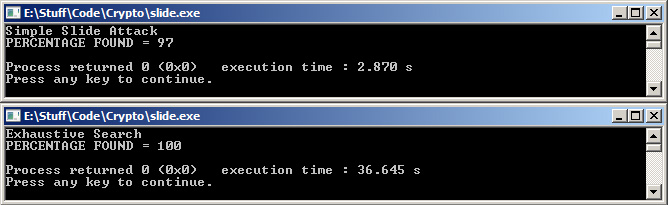
Earlier I mentioned how weak Toy100 is because of its small keysize. Anyone can brute force this thing in under a second. So how can we possibly test the slide attack against it to verify that brute involves more work? The answer is to repeat the process (generating plaintext and all) about 1000 times. Run the slide attack and time it, then do the same with the brute force method. My code does this to demonstrate that it does work well.
If you're looking for a way to take this further, try expanding the whole thing to 16-bit blocks/32-bit keys and see if the runtimes are realistic.
Comparing the work of the slide attack against exhaustive search tells us why it is much faster. With exhaustive, you must test all 2^16 keys to get 100% key recovery. Slide uses 30 plaintext-ciphertexts and checks each pair against each other pair. During each of these checks (looking for a slid pair), it must check 256 possibilities for K0 (and thus K1). The trick here is that exhaustive must do full test encryptions to check each key. Thats 100 rounds. The equivalent work for the slide method is around 4 rounds per check. Also, as more plaintext pairs are checked against each other the odds of finding a slid pair skyrocket. This is due to a phenomenon known as the Birthday Paradox.
The coolest feature in all of this is that if the cipher designer adds even more rounds. Our attack gets even stronger in relation to exhaustive search.
Hope you all enjoyed this one. If you're having trouble getting it, focus on that last diagram and how to leverage it against the weakness of the doubleround. As always, let me know how to make these pages better and stay sharp.